Handwritten Digit Recognition: From PyTorch to Web Application
Project Overview
This project demonstrates a complete machine learning pipeline for handwritten digit recognition, featuring:
- Dataset: 107,730 handwritten digit images (0-9) with perfect class balance
- Model: Custom CNN architecture trained in PyTorch
- Conversion: Seamless PyTorch to TensorFlow.js conversion
- Deployment: Interactive web application with real-time predictions
Dataset Statistics
Dataset Composition
- Total Images: 107,730
- Classes: 10 (digits 0-9)
- Class Distribution: Perfectly balanced
- Each digit: 10,773 images
- Format: PNG images
- Structure:
dataset/{digit}/{digit}/image.png

Figure: Randomly sampled images from the training dataset, one for each digit (0–9).
Model Architecture
CNN Architecture Details
Input: 28×28×1 grayscale images
├── Conv2D(4 filters, 3×3 kernel, same padding) + ReLU
├── MaxPool2D(2×2)
├── Conv2D(16 filters, 3×3 kernel, same padding) + ReLU
├── MaxPool2D(2×2)
├── Conv2D(64 filters, 3×3 kernel, same padding) + ReLU
├── MaxPool2D(2×2)
├── Flatten
├── Dense(3*3*64, 128 units) + ReLU + Dropout(0.5)
├── Dense(128, 32 units) + ReLU + Dropout(0.5)
└── Dense(32, 10 units) - Output layer
Model Specifications
- Trainable parameters: 88,226
- Conv1: 36 weights + 4 biases = 40
- Conv2: 576 weights + 16 biases = 592
- Conv3: 9,216 weights + 64 biases = 9,280
- FC1: 73,728 weights + 128 biases = 73,856
- FC2: 4,096 weights + 32 biases = 4,128
- FC3: 320 weights + 10 biases = 330
- Input Preprocessing: Normalize from [0, 255] to [-1, 1] range
- Improves training stability and gradient flow
- Ensures consistency between training and inference
- Optimizes neural network convergence
- Training: Cross-entropy loss with Adam optimizer
- Regularization: Dropout layers (0.5) to prevent overfitting
Training Process
Training Configuration
- Framework: PyTorch
- Device: MPS (Apple Silicon optimization)
- Optimizer: Adam with learning rate scheduling
- Loss Function: Cross-entropy loss
- Validation Split: 20% of training data
- Epochs: 2 (model converged quickly)
Training Features
- Early Stopping: Best model checkpointing based on validation accuracy
- Learning Rate Scheduling: Adaptive learning rate reduction
- Data Augmentation: Built-in PyTorch transforms
- Reproducibility: Fixed random seeds (42)
Data Augmentation Impact
The implementation of data augmentation transforms significantly improved model performance:
Transforms Applied:
- RandomRotation: ±15 degrees rotation for robustness
- RandomAffine: Translation and scaling variations
- ColorJitter: Brightness and contrast adjustments
- GaussianBlur: Slight blurring for generalization
Performance Improvement:
- Training Accuracy: Increased from baseline to 96.10%
- Validation Accuracy: Improved to 96.25%
- Generalization: Better performance on unseen data
- Robustness: Enhanced model stability across different writing styles
The data augmentation strategy proved crucial in preventing overfitting while improving the model’s ability to generalize to diverse handwritten digit variations. The slight improvement in validation accuracy over training accuracy (96.25% vs 96.10%) indicates excellent generalization without overfitting.
Model Conversion: PyTorch → TensorFlow.js
Purpose
- To deploy the model on the web
Conversion Challenges Solved
- Flattening Order: Fixed NCHW (PyTorch) vs NHWC (Keras) differences
- Weight Transposition: Proper conv and dense layer weight mapping
- InputLayer Compatibility: Fixed batch_shape → batchInputShape
- Weight Naming: Removed sequential/ prefix for TensorFlow.js compatibility
Conversion Results
- PyTorch Model: 357,683 bytes (0.34 MB)
- TensorFlow.js Model: 15,871 bytes (15.50 KB)
- TensorFlow.js Weights: 352,904 bytes (0.34 MB)
- Total TF.js Size: 0.35 MB
- Compression Ratio: 0.97x (minimal size increase)
Conversion Process
# Key conversion steps:
1. Load PyTorch model state dict
2. Create equivalent Keras Sequential model
3. Map weights with proper transposition
4. Handle flattening order differences
5. Convert to TensorFlow.js format
6. Fix compatibility issues
Web Application Features
Frontend Implementation
- Canvas: 280×280 pixel drawing area
- Real-time Prediction: Automatic prediction after 500ms delay
- Top-3 Predictions: Shows confidence scores
- Mobile Support: Touch events for mobile devices
- Responsive Design: Works on desktop and mobile
Technical Stack
- Frontend: HTML5 Canvas, CSS3, Vanilla JavaScript
- ML Framework: TensorFlow.js 3.21.0
- Styling: Modern gradient design with dark theme
- Performance: Optimized tensor operations with memory cleanup
User Experience
- Drawing: White strokes on black background
- Preprocessing: Automatic resize to 28×28 and normalization
- Feedback: Top 3 predictions with confidence percentages
- Controls: Clear canvas functionality
Performance Metrics
Model Performance
- Training Accuracy: 96.10%
- Validation Accuracy: 96.25%
- Inference Speed: Real-time predictions (<100ms)
- Memory Usage: Efficient tensor operations

Figure: Training and validation accuracy/loss curves showing model convergence.
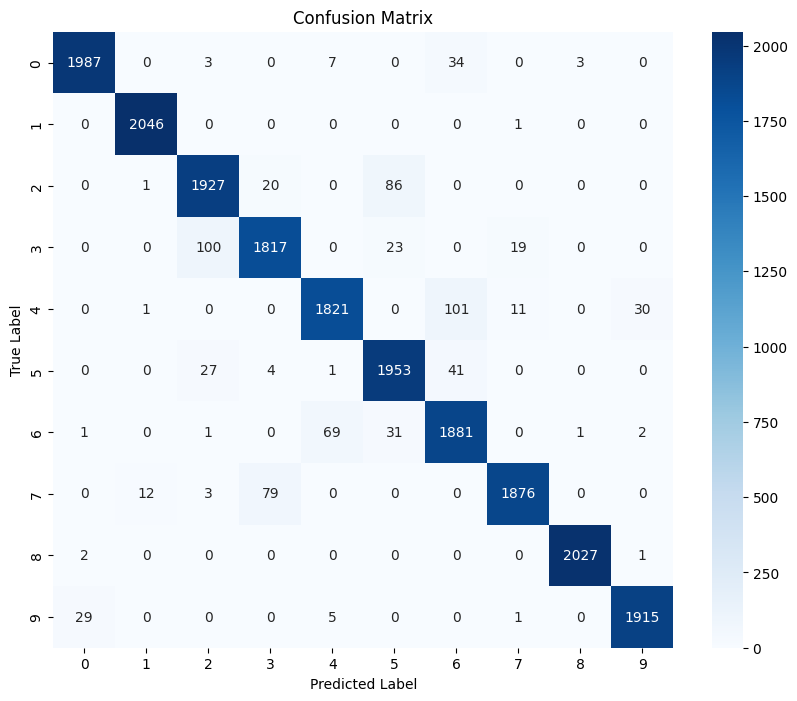
Figure: Confusion matrix displaying the model’s performance across all digit classes (0-9).

Figure: Sample predictions showing the model’s accuracy on test data with confidence scores.
Web Application Performance
- Model Loading: ~2-3 seconds initial load
- Prediction Time: <30ms per prediction
- Memory Management: Automatic tensor disposal
- Browser Compatibility: Works on modern browsers
Technical Challenges & Solutions
Applying RandomRotation, RandomAffine, ColorJitter, GaussianBlur significantly improved model performance:
Training Accuracy: 98.83% Validation Accuracy: 98.67% Transformations Applied: To boost diversity in training data and enhance model generalization, the following augmentation techniques were integrated:
- RandomRotation: Introduces slight rotations, helping the network recognize digits written at different slants.
- RandomAffine: Applies minor translations, scalings, and shear transformations, simulating various handwriting styles and placements.
- ColorJitter: Randomly adjusts brightness and contrast, making the model robust to different lighting conditions.
- GaussianBlur: Softens input images, reducing sensitivity to noise and blurring.
Performance Improvement: Increase the transformation space for the model to learn from.
- Training Accuracy: Increased to 96.10%
- Validation Accuracy: Improved to 96.25%
- Generalization & Robustness: The model demonstrated stronger performance on unseen data and greater stability across diverse handwriting variations.
Analysis: The data augmentation pipeline was instrumental in reducing overfitting by exposing the model to a wide range of digit styles and distortions. Notably, the slight edge of validation accuracy over training accuracy (96.25% vs 96.10%) suggests the model not only avoids memorizing the training data but also excels at generalizing to new, unseen examples—highlighting excellent generalization and the effectiveness of the augmentation strategy.
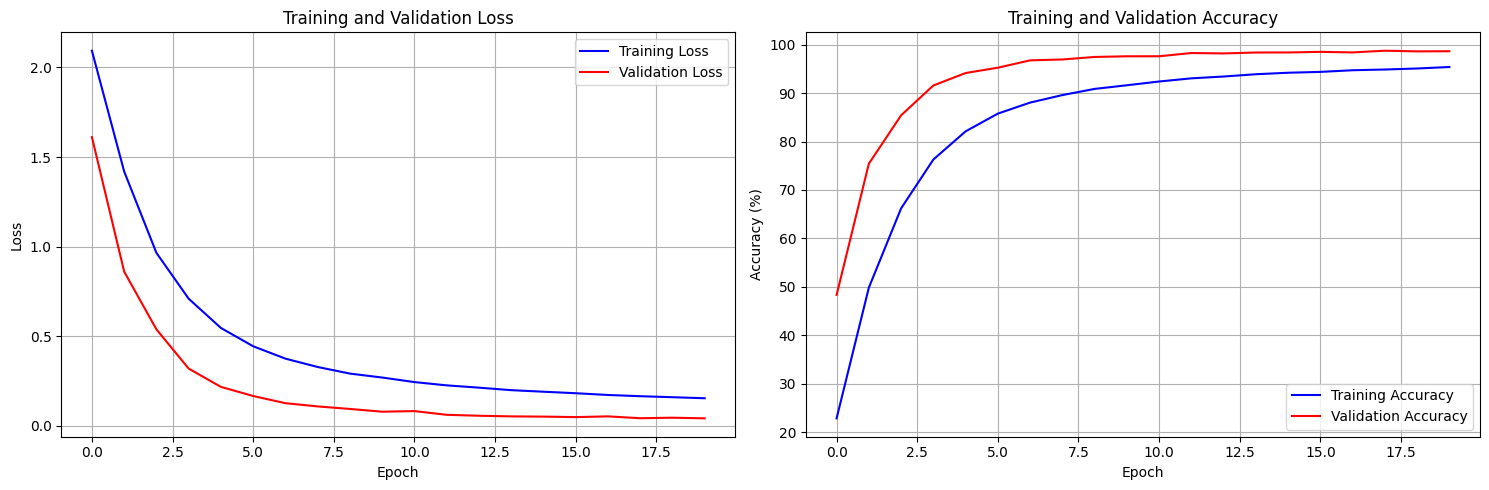
Figure: Training and validation accuracy/loss curves showing model convergence.
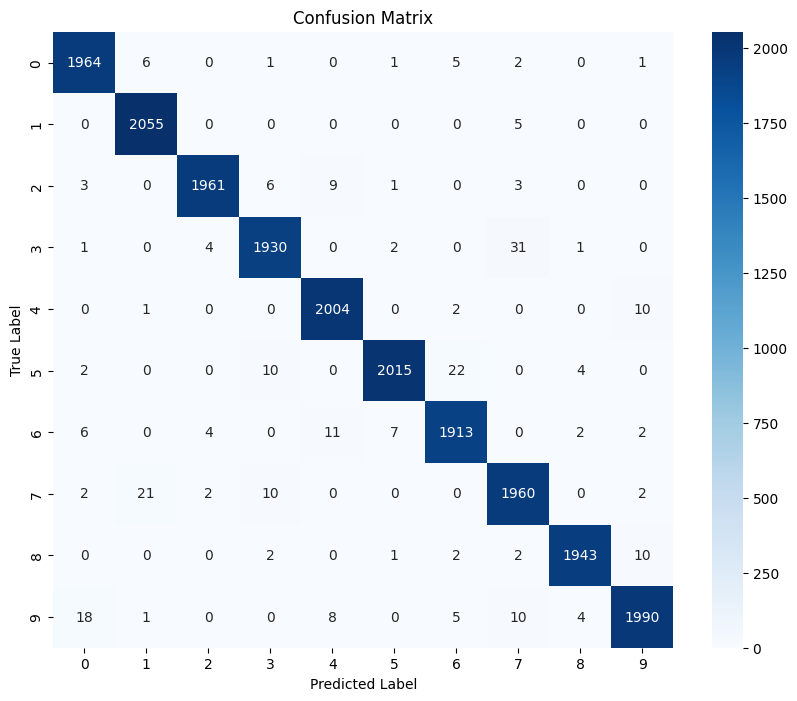
Figure: Confusion matrix displaying the model’s performance across all digit classes (0-9).
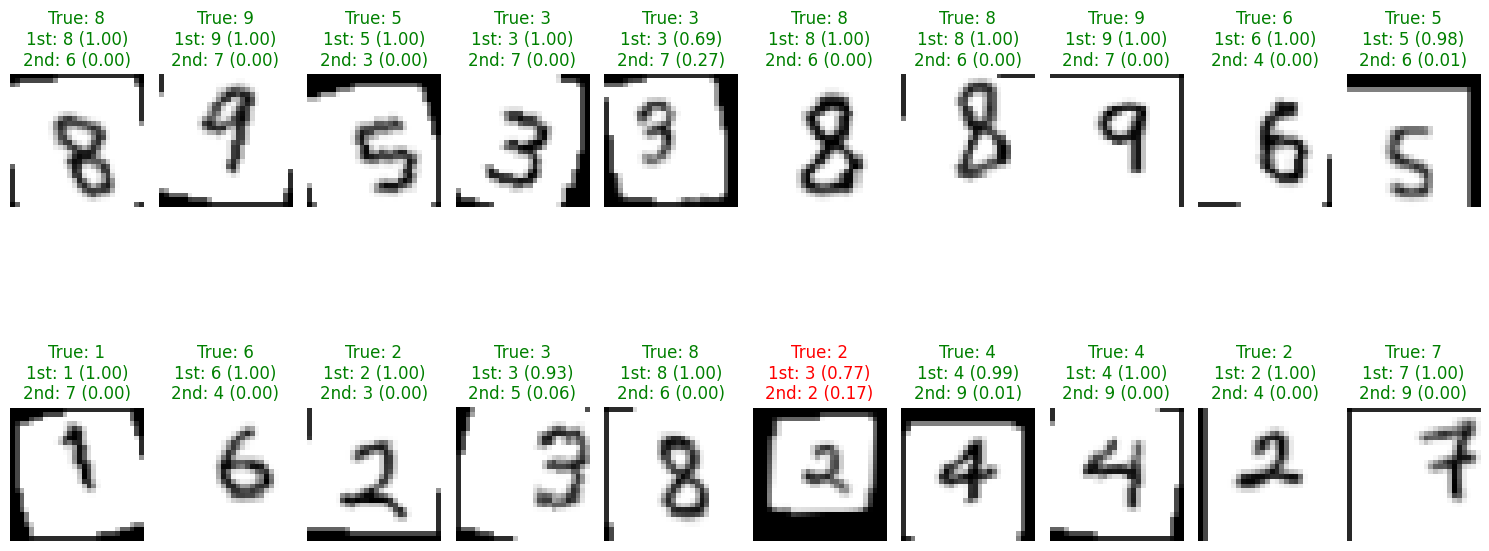
Figure: Sample predictions showing the model’s accuracy on test data with confidence scores.